|
#72 2006-04-06 15:18:37 lxml for Windows!lxml now has a Windows binary available. I'm thrilled! lxml is a fast, Pythonic XML library with full XPath support. I don't know of any other Python XML library that has all three of these attributes:
I have raved many times about dom4j, an XML library for Java which is easy to use and includes XPath support. I have long wished for a Python package as powerful and easy-to-use. I'm optimistic that lxml will fill the bill. Categories: Python |
|
#70 2005-12-28 10:49:20 Why I love Python 5Easy introspection and dynamic loadingThis example shows off several useful features of Python including introspection, dynamic loading, first-class functions and flexible except clauses. At work I have some Java code that uses XPath support from the Xalan class org.apache.xpath.XPathAPI. In Java 1.4 this class is provided with the JRE. In Java 1.5 they moved the class to com.sun.org.apache.xpath.internal.XPathAPI. I need to run with either version of Java. I prefer not to bundle Xalan with my program, so I wrote a wrapper that dynamically locates the correct version and dispatches to it:
// The XPathAPI is in different packages in Java 1.4 and 1.5.
// Use introspection to find the right one
private static Method __selectSingleNode;
static {
// Look for the XPathAPI class in two places
Class XPathAPI = null;
try {
XPathAPI = Class.forName("org.apache.xpath.XPathAPI");
} catch (ClassNotFoundException e) {
try {
XPathAPI = Class.forName("com.sun.org.apache.xpath.internal.XPathAPI");
} catch (ClassNotFoundException e1) {
}
}
// Get the methods we support
try {
__selectSingleNode =
XPathAPI.getMethod("selectSingleNode",
new Class[] { Node.class, String.class} );
} catch (SecurityException e) {
} catch (NoSuchMethodException e) {
}
}
/** XPathAPI.selectSingleNode */
public static Node selectSingleNode(Node node, String xpath) {
try {
return (Node)__selectSingleNode.invoke(null, new Object[] { node, xpath });
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
return null;
}
Wow, what an ugly mess! What would it look like in Python? The initial static block would become a conditional import: try: import org.apache.xpath.XPathAPI as XPathAPI except ImportError: import com.sun.org.apache.xpath.internal.XPathAPI as XPathAPI That was easy - and wait - we're done now! The client code can call XPathAPI.selectSingleNode() and it will work! But suppose for the sake of example we want to get a reference to selectSingleNode using introspection. That is as simple as __selectSingleNode = getattr(XPathAPI, 'selectSingleNode') This __selectSingleNode is itself a callable function (not a wrapper around a function) so clients can call it directly; the selectSingleNode() wrapper is not needed at all. I have omitted the exception handling in the Python code because these exceptions are fatal and might as well terminate the program. If I wanted to catch them I could use an except clause with multiple exception types, instead of multiple except clauses, something like this: try: __selectSingleNode = ... except (SecurityException, NoSuchMethodException), e: e.printStackTrace() |
|
#69 2005-12-06 22:37:36 Simple itertools.groupby() exampleSuppose you have a (sorted) list of dicts containing the names of cities and states, and you want to print them out with headings by state:
>>> cities = [
... { 'city' : 'Harford', 'state' : 'Connecticut' },
... { 'city' : 'Boston', 'state' : 'Massachusetts' },
... { 'city' : 'Worcester', 'state' : 'Massachusetts' },
... { 'city' : 'Albany', 'state' : 'New York' },
... { 'city' : 'New York City', 'state' : 'New York' },
... { 'city' : 'Yonkers', 'state' : 'New York' },
... ]
First let me explain operator.itemgetter(). This function is a factory for new functions. It creates functions that access items using a key. In this case I will use it to create a function to access the 'state' item of each record:
>>> from operator import itemgetter
>>> getState = itemgetter('state')
>>> getState
<operator.itemgetter object at 0x00A31D90>
>>> getState(cities[0])
'Connecticut'
>>> [ getState(record) for record in cities ]
['Connecticut', 'Massachusetts', 'Massachusetts', 'New York', 'New York', 'New York']
So the value returned by itemgetter('state') is a function that accepts a dict as an argument and returns the 'state' item of the dict. Calling getState(d) is the same as writing d['state']. What does this have to do with itertool.groupby()? >>> from itertools import groupby >>> help(groupby) Help on class groupby in module itertools: class groupby(__builtin__.object) | groupby(iterable[, keyfunc]) -> create an iterator which returns | (key, sub-iterator) grouped by each value of key(value). groupby() takes an optional second argument which is a function to extract keys from the data. getState() is just the function we need. >>> groups = groupby(cities, getState) >>> groups <itertools.groupby object at 0x00A88300> Hmm. That's a bit opaque. groupby() returns an iterator. Each item in the iterator is a pair of (key, group). Let's take a look: >>> for key, group in groups: ... print key, group ... Connecticut <itertools._grouper object at 0x0089D0F0> Massachusetts <itertools._grouper object at 0x0089D0C0> New York <itertools._grouper object at 0x0089D0F0> Hmm. Still a bit opaque :-) The key part is clear - that's the state, extracted with getState - but group is another iterator. One way to look at it's contents is to use a nested loop. Note that I have to call groupby() again, the old iterator was consumed by the last loop:
>>> for key, group in groupby(cities, getState):
... print key
... for record in group:
... print record
...
Connecticut
{'city': 'Harford', 'state': 'Connecticut'}
Massachusetts
{'city': 'Boston', 'state': 'Massachusetts'}
{'city': 'Worcester', 'state': 'Massachusetts'}
New York
{'city': 'Albany', 'state': 'New York'}
{'city': 'New York City', 'state': 'New York'}
{'city': 'Yonkers', 'state': 'New York'}
Well, that makes more sense! And it's not too far from the original requirement, we just need to pretty up the output a bit. How about this:
>>> for key, group in groupby(cities, getState):
... print 'State:', key
... for record in group:
... print ' ', record['city']
...
State: Connecticut
Harford
State: Massachusetts
Boston
Worcester
State: New York
Albany
New York City
Yonkers
Other than misspelling Hartford (sheesh, and I grew up in Connecticut!) that's not too bad! Categories: Python |
|
#66 2005-10-24 21:14:40 What's so great about Ruby?I'm reading Bruce Tate's latest book, Beyond Java. In it, he argues that Java has become overgrown, unwieldy and vulnerable for replacement in many applications. Prime candidates to replace it are the dynamic languages, particularly Ruby. As a staunch Python advocate I read his description of Ruby with interest. Most Ruby features that he thinks are cool are available in Python in some form. Some are considered wizard-level tricks in Python instead of the mainstream practices they seem to be in Ruby. For example, in Ruby you can easily add to a class definition. You just declare the class again and extend the definition. This works even for built-in classes. The Ruby approach is conceptually very simple--it reuses the class definition syntax. In Python you can add methods to a class after it is defined by adding attributes to the class. Python's approach is fairly obscure - getting it right can take a few tries. Ruby allows mixins--class fragments that can be added to a class definition to extend it. Python can do the same with multiple inheritance, at the time a class is defined, or by appending to __bases__, which might be considered a hack. Ruby has support for creating aliases of methods and replacing them, and this is considered a good thing. In Python this is called monkeypatching and is generally frowned on. So there is not that much difference in capability. In Ruby some of these things are easier, and I don't discount that. But the main difference seems to be philosophical or cultural. In Python classes are thought of as fairly static--once you create it, it's done. Metaprogramming tricks are used during class creation to get some special effect, or to meet some unusual need. In Ruby, though, classes are thought of as malleable. A class definition is just a starting point for the full functionality of the class. It's an interesting way of looking at it. Categories: Python |
|
#64 2005-06-10 09:24:16 Why I love Python 4Sometimes Java almost seems to go out of its way to make coding difficult, while Python goes out of its way to make it easy. Here is a case in point. I needed a Java method that accepts a duration expressed as a number of minutes in a string, and returns the same duration formatted as HH:MM:SS. In Python, this is trivial: def formatDuration(durStr): hours, minutes = divmod(int(durStr), 60) return '%02d:%02d:00' % (hours, minutes) Java, on the other hand, makes me jump through hoops to do the same thing:
static String formatDuration(String spcsfDur) {
int duration = Integer.parseInt(spcsfDur);
int minutes = duration % 60;
int hours = (duration - minutes) / 60;
Object[] args = new Object[] {
new Integer(hours),
new Integer(minutes)
};
String durStr = MessageFormat.format("{0,number,00}:{1,number,00}:00", args);
return durStr;
}
Ouch. Categories: Python |
|
#61 2004-10-22 20:40:32 When should I use classes?A question beginners sometimes ask is, "Should I use classes in my program?" This article gives some ideas of when it is appropriate to introduce classes into a design. Categories: Python |
|
#60 2004-10-19 15:18:24 ReliefIt's such a relief to be coding in Jython again after working with Java. In Java I feel like I'm fighting the language and the APIs all the time. It's way too hard to get anything done. Python just does what I want with much less straining and fuss. Aaahhh! |
|
#58 2004-10-06 19:53:36 Spring FreeFor my current project, a distributed application with a database back-end, I tried Hibernate and Spring. I really wanted to like them! They have lots of cool features and make some things incredibly easy. But in the end I have gone back to tried-and-true simple tools - Jython, Velocity, Jetty and not much else. Hibernate felt like it got in the way as much as it helped. I was constantly having to figure out the Hibernate way of things. My data is largely a tree structure flattened into a database table. Hibernate's lazy loading was sometimes great and sometimes exactly wrong. Spring just felt too big. Every time I needed a new piece I would have to add another Spring jar to my lib directory and usually a few more jars that it depended on. It felt like using a sledgehammer to squash an ant. Java also feels quite cumbersome now. I have been working primarily in Jython for about a year now and I hate the hoops that Java makes me jump though to get anything done. In the end it all felt too confining. I was Mech Warrior, high in a robot programming vehicle, directing awesome power from from my command post. But I longed to put my feet on the ground, pick up a light pack and run. So I have chucked it all, salvaging what I can, starting over for the rest. What a relief it is! |
|
#57 2004-09-14 21:29:36 Python and UnicodePython has extensive support for Unicode data. Two issues that are not well documented elsewhere are the handling of non-Ascii characters in the Python interpreter, and use of the default system encoding. I cover those here. Categories: Python |
|
#56 2004-08-27 23:39:44 concat vs join - followupA couple of people have made good points about my last post comparing string concatenation and join. Marilyn Davis pointed out that in my data, the crossover point where join beats concatenation is always around 500 total characters in the final string. Hans Nowak pointed out that for much longer strings such the lines of a file or parts of a web page, the crossover point comes very quickly. So here is ConcatTimer version 2 :-) This version dispenses with the fancy graphics and just looks for the crossover point. (It's not too smart about it, either.) It also looks at much larger text chunks - up to 80 characters. Here is the program:
import timeit
reps = 100 # How many reps to try?
unit = ' ' # Concat this string
# Naive concatenation using string +
def concatPlus(count):
s=''
for i in range(count):
s += unit
return s
# Concatention with string.join
def concatJoin(count):
s=[]
for i in range(count):
s.append(unit)
return ''.join(s)
# Time one test case
def timeOne(fn, count):
setup = "from __main__ import " + fn.__name__
stmt = '%s(%d)' % (fn.__name__, count)
t = timeit.Timer(stmt, setup)
secs = min(t.repeat(3, reps))
return secs
# For strings of length unitLen, find the crossover point where appending
# takes the same amount of time as joining
def findOne(unitLen):
global unit
unit = ' ' * unitLen
t = 2
while 1:
tPlus = timeOne(concatPlus, t)
tJoin = timeOne(concatJoin, t)
if tPlus > tJoin:
break
t += 1
return t, tPlus, tJoin
for unitLen in range(1,80):
t, tPlus, tJoin = findOne(unitLen)
print '%2d %3d %3d %1.5f %1.5f' % (unitLen, t, t*unitLen, tPlus, tJoin)
And here is an elided list of results. The columns are the length of the pieces, the number of pieces where concat becomes more expensive than join, the total number of characters in the string at the crossover point, and the actual times. (I cut the number of reps down to keep this from taking too long to run.) 1 475 475 0.02733 0.02732 2 263 526 0.01581 0.01581 3 169 507 0.01024 0.01022 4 129 516 0.00782 0.00778 5 100 500 0.00622 0.00604 6 85 510 0.00517 0.00515 7 73 511 0.00447 0.00446 8 63 504 0.00386 0.00385 9 57 513 0.00354 0.00353 10 53 530 0.00333 0.00333 11 47 517 0.00294 0.00292 12 45 540 0.00287 0.00285 13 41 533 0.00262 0.00260 14 38 532 0.00246 0.00244 15 36 540 0.00232 0.00230 16 34 544 0.00222 0.00222 17 31 527 0.00200 0.00199 18 29 522 0.00189 0.00188 19 30 570 0.00199 0.00194 20 28 560 0.00188 0.00186 21 28 588 0.00190 0.00185 22 26 572 0.00177 0.00174 23 25 575 0.00170 0.00168 24 24 576 0.00165 0.00163 25 23 575 0.00158 0.00156 26 22 572 0.00153 0.00151 27 21 567 0.00146 0.00144 28 21 588 0.00146 0.00146 29 21 609 0.00147 0.00144 30 20 600 0.00142 0.00139 31 19 589 0.00134 0.00134 32 20 640 0.00143 0.00139 33 19 627 0.00137 0.00136 34 18 612 0.00130 0.00129 35 18 630 0.00131 0.00130 36 18 648 0.00133 0.00130 37 17 629 0.00126 0.00126 38 17 646 0.00126 0.00124 39 15 585 0.00112 0.00111 43 15 645 0.00113 0.00110 44 14 616 0.00106 0.00105 45 15 675 0.00114 0.00110 46 14 644 0.00106 0.00105 48 14 672 0.00109 0.00105 49 13 637 0.00100 0.00099 58 13 754 0.00104 0.00100 59 12 708 0.00098 0.00096 69 12 828 0.00102 0.00098 70 11 770 0.00093 0.00092 77 11 847 0.00094 0.00091 78 10 780 0.00086 0.00086 79 10 790 0.00087 0.00085 So, for anyone still reading, you can see that Hans is right and Marilyn is close:
Based on this experiment I would say that if the total number of characters is less than 500-1000, concatenation is fine. For anything bigger, use join. Of course the total amount of time involved in any case is pretty small. Unless you have a lot of characters or you are building a lot of strings, I don't think it really matters too much. I started this experiment because I have been telling people on the Tutor mailing list to use join, and I wondered how much it really mattered. Does it make enough of a difference to bring it up to beginners? I'm not sure. It's good to teach best practices, but maybe it's a poor use of time to teach this to beginners. I won't be so quick to bring it up next time. Update: Alan Gauld points out that this is an optimization, and the first rule of optimization is don't until you know you need it. That's a useful way to think about it. Thanks for the reminder! Categories: Python |
|
#55 2004-08-27 19:49:20 Which is really faster - concatenation or join?A couple of times recently I have given out the conventional advice that for concatenating strings, it is better to build a list of the pieces and join it together than to use string concatenation to build the list. The reasoning is that string concatenation requires copying the entire string for each addition, while the list is designed to make concatenation efficient. Because of all the copying, the time for string concatenation is proportional to the square of the number of additions - it is O(n^2). List append, however, happens in constant time, so building the list takes time proportional to the number of appends - it is O(n). The trick with this, though, is that there is a proportionality constant here, and for small n, string concatenation may be faster. I decided to find out. Here is a program that compares the time for string concatenation using the two methods. It varies both the number of append operations and the length of the appended strings. It prints the results in a series of tables, and it uses VPython to graph the results:
import timeit
from visual.graph import *
reps = 1000 # How many reps to try?
unit = ' ' # Concat this string
# Naive concatenation using string +
def concatPlus(count):
s=''
for i in range(count):
s += unit
return s
# Concatention the way the big boys do it, with string.join
def concatJoin(count):
s=[]
for i in range(count):
s.append(unit)
return ''.join(s)
# Time one test case
def timeOne(fn, count):
setup = "from __main__ import " + fn.__name__
stmt = '%s(%d)' % (fn.__name__, count)
t = timeit.Timer(stmt, setup)
secs = min(t.repeat(3, reps))
return secs
# Draw the curves for a single length of the appended string
def graphOne(unitLen):
global unit
unit = ' ' * unitLen
title = 'Unit length is %d' % len(unit)
funct1 = gcurve(color=color.cyan)
funct2 = gdots(color=color.yellow)
print
print title
print ' tPlus tJoin'
for t in range(10, 100, 10) + range(100, 600, 50):
tPlus = timeOne(concatPlus, t)
tJoin = timeOne(concatJoin, t)
print '%5d %2.3f %2.3f' % (t, tPlus, tJoin)
funct1.plot( pos=(t, tPlus) )
funct2.plot( pos=(t, tJoin) )
graph = gdisplay(title='Append speed', xtitle='count', ytitle='time')
for unitLen in [1,2,3,4,5]:
graphOne(unitLen)
Here is the graph - the yellow dots are for concatJoin, the blue curves are concatPlus: 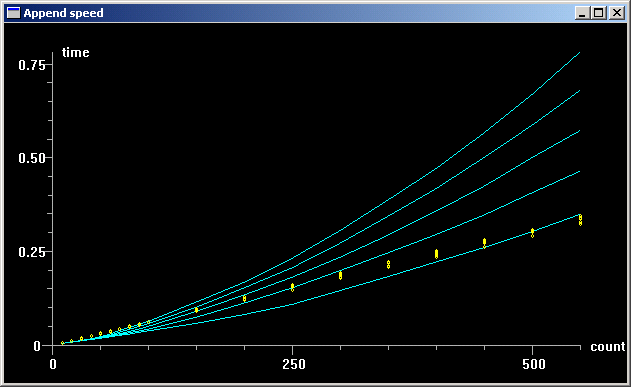
A couple of things stand out from this:
Based on these results, I think I will stop spreading the conventional wisdom. I think most uses of string concatenation are for small strings with a small number of concatenations. String join only pays off when there are a lot of appends. Here is the raw data from the program:
D:\Personal\Tutor>python concattimer.py
Visual-2003-10-05
Unit length is 1
tPlus tJoin
10 0.005 0.008
20 0.008 0.014
30 0.012 0.020
40 0.015 0.025
50 0.018 0.032
60 0.022 0.037
70 0.026 0.044
80 0.029 0.049
90 0.033 0.057
100 0.038 0.062
150 0.059 0.092
200 0.082 0.122
250 0.109 0.149
300 0.145 0.178
350 0.184 0.208
400 0.222 0.237
450 0.262 0.264
500 0.307 0.292
550 0.349 0.325
Unit length is 2
tPlus tJoin
10 0.005 0.008
20 0.008 0.014
30 0.012 0.019
40 0.015 0.026
50 0.019 0.033
60 0.023 0.039
70 0.027 0.044
80 0.033 0.051
90 0.038 0.057
100 0.042 0.062
150 0.075 0.095
200 0.114 0.125
250 0.155 0.154
300 0.200 0.185
350 0.247 0.215
400 0.295 0.243
450 0.349 0.272
500 0.404 0.305
550 0.463 0.332
Unit length is 3
tPlus tJoin
10 0.005 0.008
20 0.008 0.014
30 0.012 0.019
40 0.016 0.026
50 0.020 0.033
60 0.025 0.039
70 0.031 0.045
80 0.036 0.051
90 0.043 0.057
100 0.050 0.064
150 0.090 0.095
200 0.134 0.127
250 0.184 0.159
300 0.236 0.187
350 0.293 0.217
400 0.360 0.247
450 0.427 0.278
500 0.499 0.306
550 0.576 0.335
Unit length is 4
tPlus tJoin
10 0.005 0.008
20 0.008 0.014
30 0.012 0.019
40 0.017 0.025
50 0.021 0.033
60 0.026 0.039
70 0.035 0.045
80 0.042 0.051
90 0.050 0.058
100 0.057 0.063
150 0.101 0.096
200 0.153 0.129
250 0.207 0.161
300 0.271 0.192
350 0.341 0.222
400 0.416 0.249
450 0.501 0.280
500 0.580 0.310
550 0.682 0.338
Unit length is 5
tPlus tJoin
10 0.005 0.008
20 0.008 0.014
30 0.013 0.019
40 0.017 0.025
50 0.022 0.034
60 0.029 0.040
70 0.040 0.046
80 0.047 0.052
90 0.055 0.058
100 0.063 0.064
150 0.114 0.097
200 0.169 0.130
250 0.232 0.163
300 0.306 0.195
350 0.385 0.223
400 0.470 0.252
450 0.567 0.283
500 0.668 0.313
550 0.779 0.344
Categories: Python |

Comments about life, the universe and Python, from the imagination of Kent S Johnson.

BlogRoll
